
Introduction
In order to extract useful information from the ocean of linguistic big data, the technique of text mining is used. Once the data has been retrieved, it is transformed into a structured format that may be used for additional analysis or displayed in a more straightforward manner by means of clustered HTML tables of information, mind maps, graphs, etc. Among the many methods online assignment help Luton and text mining, “Natural Language Processing (NLP)” stands out as crucial to understanding the text. In this essay, the following sections will describe the benefits of text mining, how the feature are extracted for the predictive analysis, the modeling process, text-based predictive analysis, and the applications and recommendations. In the end, there will be a conclusion.
Text mining value and benefits
Value
Text mining is needed to understand and use these massive informational and data resources. Access, assess, annotate, and relate the resources firstly. Data may be “mined” for patterns or new knowledge after processing. Format determines how data and other sources are evaluated (Amiri et al., 2021). Structured data is easier to “mine” since it aids processing. However, automating document analysis using a computer is tough. Most electronic files are unstructured language with flat data, which computers cannot effectively interpret.
Benefits
- Due to computational constraints, unrestricted comments are useless. Text mining quantifies this information. You receive prominence compared to fragments of remark sentiment.
- The open-ended comments along with additional verbatim remarks are essential for optimising user, consumer, client, employee, and additional stakeholder experiences (Onan, 2021). Text mining may help to comprehend stakeholder needs and reactions.
- Customer experience optimization is crucial in competitive markets. Understanding customers’ motivations, feelings, and goals can boost their level of satisfaction.
- Many text analysis tasks may be automated, saving resources. With NLP alongside other AI technologies, text mining software handles coding, sentiment evaluation, and other laborious duties.
- Custom screens with key data reduce signal to noise. Each project participant may access data to support their opinion (Hickman et al., 2022). These dashboards provide valuable visualisations and simple data access for non-data scientists.
- Boost Efficiency Automation reduces manual procedures, which may disconnect scientists with data alongside other qualified data workers. A speedier text mining algorithm increases productivity and optimises worker time.
Feature extraction and text preprocessing
Tokenization is the act of separating a piece of text into smaller units, called tokens. Tokens may be single words, phrases, or even whole sentences. Sometimes, the operation may also remove punctuation and other special characters (such as %, &, and $).
Figure 1: Tokenization for text-mining
(Source: slideteam.net, n.d)
Stemming is the frequency with which a given word appears in a given document is indicated by the term frequency. A term may be a single word or a phrase made up of many words and with help of online assignment help Manchester. A word may occur more often in larger texts than in smaller ones due to the fact that document length varies (Churchill and Singh, 2021). To normalize the frequency of a phrase, just divide the number of occurrences by the total amount of phrases in the text. People may calculate the phrase’s frequency by dividing the number of occurrences by the total number of words in the text. When words are stemmed, they are broken down into their simplest components.
Lemmatization may occur when using basic suffix rules for stemming and marketing dissertation help Birmingham. This issue may be avoided with the use of lemmatization, a more involved method of locating word stems. The lexical class (part of speech) of a word determines the normalization rule that will be used during lemmatization. By doing so, the stemmer is better able to understand the word getting stemmed and appropriately classify it with other words of a similar kind.
Text classification and modelling for predictive analysis
Preparing Data and Developing Features
Data preparation is crucial before attempting text categorization and modelling. This entails operations like tokenization, stemming, stop-word removal, and dealing with punctuation and other special characters (Müller et al., 2022). The quality of the text data used for analysis depends on how well it has been pre-processed.
Important characteristics are retrieved from the text data using a process called feature engineering. Methods like bag-of-words, “Term Frequency-Inverse Document Frequency (TF-IDF)”, and embeddings of words such Word2Vec and GloVe fall under this category. Improved predictive model accuracy and better text data presentation are the results of careful feature engineering.
Optional Models and Algorithms
Depending on the needs and nature of the data, many methods and models may be used for text categorization and modelling. Naive Bayes, “Support Vector Machines (SVM)”, Random Forest, as well as deep learning models like “Recurrent Neural Networks (RNN)” and “Convolutional Neural Networks (CNN)” are only some of the most popular algorithms utilised today (Aldino et al., 2021). Considerations such as dataset size, task complexity, and the need for interpretability should inform the choice of methods. Although effective, deep learning models often need for a substantial quantity of labelled data and processing capacity.
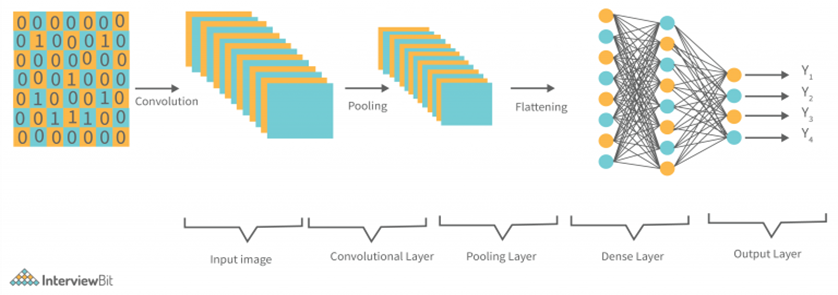
Figure 2: CNN architecture
(Source: interviewbit)
Analyses and improvements
Metrics like as precision, recall, and F1-score are used to assess the efficacy of text categorization and modelling approaches. These metrics measure how well a model can place text input into categories or generate predictions.
Improve the accuracy and generalization of the models by using model optimisation approaches like hyperparameter tweaking, cross-validation, and ensemble methods. This makes sure the algorithms can accurately anticipate new text data without seeing it before.
Text-based Predictive models and their applications
Sentiment analysis
One common usage of prediction models built on text is sentiment analysis. Insights about consumer attitudes, brand reputation, and general opinion towards goods or services may be gleaned from the text data classified by these algorithms as favourable, adverse, or neutral. Applications of sentiment analysis include listening to online conversations, analysing consumer feedback, and handling public perception.
Predicting Customer Attrition
Predictive models trained on textual data, including customer service requests, chat logs, or social media interactions, may assist pinpoint clients most at danger of leaving (Jayalekshmi, 2023). Organisations may take preventative measures to retain consumers and boost customer satisfaction by using predictive modelling approaches to extract useful elements from these messages.
Identifying Spam
Email filters as well as messaging services often utilise text-based prediction algorithms for spam detection. These models examine e-mails’ contents to spot and eliminate spam and other potentially harmful communications; this improves the customer’s experience and keeps sensitive information safe.
Clustering of Documents and Topic Modelling
Topic modelling and document grouping are two applications of text-based prediction algorithms that group documents with comparable content altogether. In order to facilitate effective information retrieval, material recommendation, and content comprehension, these models aid in the organisation and categorization of vast collections of information.
Finding Conspiracies
Fraud detection tools may use text-based prediction models to examine textual data including transaction descriptions, client profiles, and communication logs (Fong et al., 2021). These models may aid in the fight against fraud by spotting red flags in the form of trends and outliers in textual information.
Classification of News Stories
Predictive models trained on text data may classify news stories automatically by subject or domain. This software aids news outlets, content aggregators of and systems for recommendation in delivering personalised information to consumers.
Recommendation
- Tokenize, stop-word remove, stem, and handle special characters including symbols in a sophisticated text preparation pipeline. This cleans and standardizes text data for analysis.
- Use bagging or enhancing to integrate various mining of texts models. Ensemble approaches use various views and reduce biases to improve model prediction and robustness.
- Text mining should include domain-specific experience and knowledge. Domain-specific dictionary entries, the ontologies or specific rules may increase the accuracy of predictions and relevance (Moreno and Caminero, 2022).
- Use metrics as well as validation methods to examine text mining models periodically. Adapt and tweak the models depending on fresh data and input to keep they working and in line with textual trends.
- Through academic papers, seminars, and industry forums, stay current on text mining as well as predictive analysis. Stay abreast of new methods, tools, including algorithms to improve text mining predictions of models.
Conclusion
Text mining is essential for making sense of and making use of these vast stores of data and information. Get to them, evaluate them, annotate them, and put them in context. Once data has been processed, it may be “mined” for hidden insights or patterns. The evaluation of data and other sources is determined by their format. In order to “mine” information more efficiently, structured data must be used. Before trying text classification and modelling, it is essential to prepare the necessary data. Tokenization, stemming, stop-word removal, and handling punctuation and other special characters are all part of the process. The effectiveness of the analysis relies on the quality of the pre-processed text data. Model optimisation strategies, including as hyperparameter tuning, cross-validation, and ensemble techniques, may be used to boost the models’ precision and scalability. By doing so, we ensure that the algorithms can correctly predict new text data without having seen it previously.
Reference
Aldino, A.A., Saputra, A., Nurkholis, A. and Setiawansyah, S., 2021. Application of Support Vector Machine (SVM) Algorithm in Classification of Low-Cape Communities in Lampung Timur. Building of Informatics, Technology and Science (BITS), 3(3), pp.325-330. https://ejurnal.seminar-id.com/index.php/bits/article/download/1041/761
Amiri, M., Deckert, M., Michel, M.C., Poole, C. and Stang, A., 2021. Statistical inference in abstracts of 3 influential clinical pharmacology journals analysed using a text‐mining algorithm. British Journal of Clinical Pharmacology, 87(11), pp.4173-4182. https://bpspubs.onlinelibrary.wiley.com/doi/pdfdirect/10.1111/bcp.14836
Churchill, R. and Singh, L., 2021, January. textprep: A text preprocessing toolkit for topic modeling on social media data [textprep: A text preprocessing toolkit for topic modeling on social media data]. In Proceedings of the 10th International Conference on Data Science, Technology and Applications. https://par.nsf.gov/servlets/purl/10280456
Fong, A., Roozenbeek, J., Goldwert, D., Rathje, S. and van der Linden, S., 2021. The language of conspiracy: A psychological analysis of speech used by conspiracy theorists and their followers on Twitter. Group Processes & Intergroup Relations, 24(4), pp.606-623. https://journals.sagepub.com/doi/pdf/10.1177/1368430220987596
Hickman, L., Thapa, S., Tay, L., Cao, M. and Srinivasan, P., 2022. Text preprocessing for text mining in organizational research: Review and recommendations. Organizational Research Methods, 25(1), pp.114-146. https://journals.sagepub.com/doi/pdf/10.1177/1094428120971683
Jayalekshmi, K.R., 2023. A COMPARATIVE ANALYSIS OF PREDICTIVE MODELS USING MACHINE LEARNING ALGORITHMS FOR CUSTOMER ATTRITION IN THE MOBILE TELECOM SECTOR. The Online Journal of Distance Education and e-Learning, 11(1). https://tojdel.net/journals/tojdel/articles/v11i01c02/v11i01-01.pdf
Moreno, A.I. and Caminero, T., 2022. Application of text mining to the analysis of climate-related disclosures. International Review of Financial Analysis, 83, p.102307. https://repositorio.bde.es/bitstream/123456789/14185/1/dt2035e.pdf
Müller, M., Longard, L. and Metternich, J., 2022. Comparison of preprocessing approaches for text data in digital shop floor management systems. Procedia CIRP, 107, pp.179-184. https://www.sciencedirect.com/science/article/pii/S2212827122002463/pdf?md5=fa37e647d9ba461c383bcf3883adf90f&pid=1-s2.0-S2212827122002463-main.pdf
Onan, A., 2021. Sentiment analysis on massive open online course evaluations: a text mining and deep learning approach. Computer Applications in Engineering Education, 29(3), pp.572-589. https://www.researchgate.net/profile/Aytug-Onan-2/publication/341156027_Sentiment_analysis_on_massive_open_online_course_evaluations_A_text_mining_and_deep_learning_approach/links/6076e8b3f41f751f32387634/Sentiment-analysis-on-massive-open-online-course-evaluations-A-text-mining-and-deep-learning-approach.pdf