
Introduction to Machine learning

According to the report (Bell, 2022.), Machine learning is known as the programming of computers for optimizing the performance criterion with the use of examples of previous experiences or past data sources. People have a model for defining some parameters by executing the learning experience for the purpose to optimize the parameters of that defined model with the use of previous experiences and past training data. The model might be predictive in sense of making future predictions and diploma of community services assignment help for the future with the descriptive range of gaining new knowledge from data. This field of study is termed machine learning which is concerned with the query of knowing the way to construct computerized programs which automatically improvise the experience.
In the area of machine learning and college essay writing service gold coast, that is a branch of artificial intelligence, including the computational methods, and analytical algorithms are created so that computers can learn from their experiences how to perform tasks better. These models and algorithms are built for learning from data sources and prepare the predictions or choices where there is no explicit definition has been added. Machine learning can also be categorized into supervised learning as well as unsupervised learning among others. Unsupervised learning includes training a model on unlabeled data, whereas supervised learning uses labelled data for training the model.
Introduction to Supervised learning

The use of labelled data specifies the “supervised learning” approach to machine learning (alteryx. 2023). These information – based points are intended to instruct or “supervise” computation in precisely knowledge in order or predicting outcome measures. The use of labelled inputs and results enables the model to ascertain its precision and augment over time. An input-to-output mapping function is learned, for example, through reinforcement methods with reflective combinations. The details offered are classified. Stagnation and categorisation are both concerns with reinforcement methods.
Discussion with an example: Having input variables (like x) and output variables (like Y) as well as a computation to map the input to the output means allowing a model to be learned under supervision. then, if Y = f (X) (Soni, (2020). The prime focus is to resemble the mapping function so that the affiliated output variable can be anticipated in the case of new input data (x). The process of learning is analogous to an instructor who supervises the entire educational process, resulting in it being known as reinforcement methods. The “learning algorithm” thus iteratively makes predictions on the training data and receives corrections from the “instructor,” and the learning process comes to an end when the algorithm performs at an acceptable level.
The task is to group fruits of the same kind together in a basket that is filled with fresh fruit. Assume the fruits are banana, cherry, apple, and grape as well. Assuming that person is already aware of the shape of each and every fruit in the basket from their previous knowledge or experience, making it simple for them to group fruits of the same type together. In this context, prior work is made reference to as training data in the data mining language. As a result, it gains knowledge from the training data. This is due to the response variable, which states that if a fruit has certain characteristics, it is a grape, and vice versa for all other fruits.
Introduction to Unsupervised learning
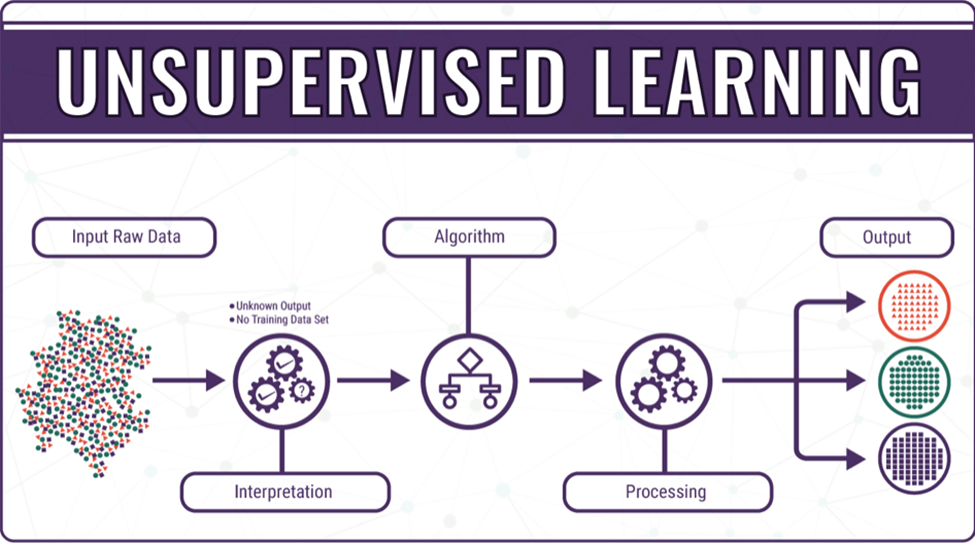
Machine learning algorithms are applied to unlabeled data sets during unsupervised learning to evaluate and constellation them. Without the help of humans, these algorithms find hidden patterns in data. A type of machine learning algorithm that can be used to’s strategy is unsupervised learning (geeksforgeek. 2023). It uses input data datasets without responsive to the needs. Unsupervised learning algorithms do not categorise or characterise the observational data. For Instance, taking into account the following statistics on clinic visitors. The patient demographics include their demographic factors.
Discussion with examples: Unsupervised learning occurs when only the input data X is prevalent and there is no correlating target value (IBM. 2023). Unsupervised learning’s primary objective is to model the data’s distribution in order to gain a better understanding of the data. It is so school age education and care assignment help named because there is no right answer and no such teacher . The interesting structure in the data is left up to the algorithms to find and display. Consider a basket that is full of fresh fruits as another example of unsupervised learning.
Arranging fruits of the same type together in one location is the task. This time, there was no prior knowledge of those fruits; they are only now being observed or discovered. Finding a method by which similar fruits can be grouped together without prior knowledge is the main concern in this situation. The first step is choosing a fruit’s physical attributes. Imagine color. After that, the fruits are arranged according to color. The groups will look something like this: Apples and cherries are in the RED color group. Bananas and grapes are in the green color group. Take size as an example of another physical characteristic, and the groups will now look something like this. Apple: BIG AND RED, in color. Cherry fruits are RED AND SMALL IN SIZE. Bananas are BIG and GREEN in color. Grapes are small, green, and colored. It’s finished! No prior knowledge or education is required in this situation. No train data and no response variable are used in this kind of unsupervised learning, so to speak.
Comparison between Supervised and Unsupervised machine learning
There are two categories of supervised machine learning which are classification and another is regression and two are stated in the following.
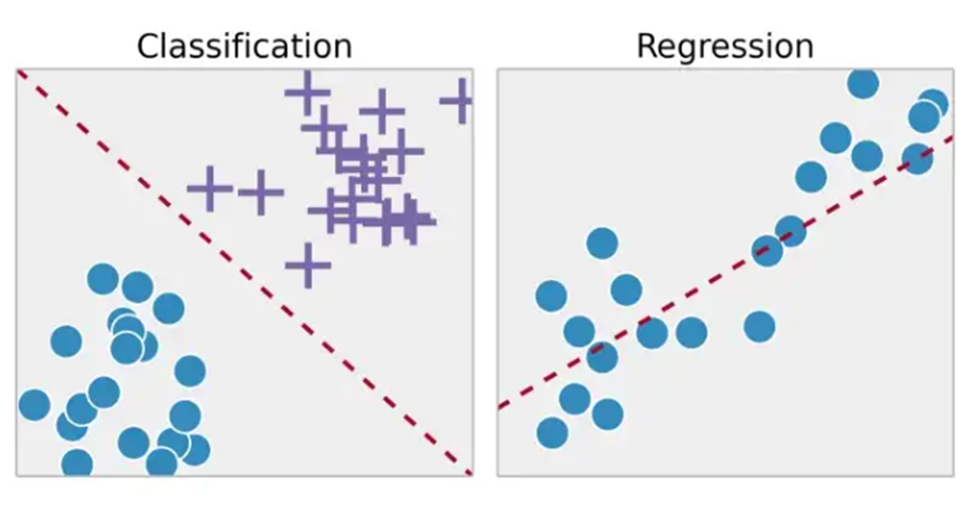
Classification
Test data is correctly classified using an automated process in classification tasks like isolating apples from oranges. In the actual world, users could also employ supervised training algorithms to spot spam and store it somewhere other than their mailbox. The four most popular types of different classifiers are judgement tree branches, linear classifiers, support vector machines, and regression trees.
Regression
Regression is a distinct kind of supervised machine learning method that uses a method to understand the connection between both independent and dependent variables (Osisanwo et al., 2017). Regression models can predict numbers utilizing a variety of data points, such as sales revenue projections for a single business. Regression algorithms that are frequently used include supply chain, regression models, and linear regression.
Clustering, Dimensionality reduction and association are three different categories of the type of unsupervised machine learning technique

Clustering
Unmarked data can be grouped together using data mining techniques such as clustering with similarities or distinctions. The K value in K-means clustering algorithms, which separate related data points into clusters, indicates the size and level of the grouping (Sreedhar, et al., 2017). This method is useful for data compression and market dynamics, among other things.
Association
An association is a type of unsupervised learning technique that engages a number of rules to discover relationships between variables in a given dataset.
Dimensionality reduction
When a dataset has an excessive number of attributes (or measurements), a learning technique called “dimensionality reduction” is used (Salo et al., 2019). While lowering the number of data inputs to a manageable level, the data integrity is maintained. This technique is frequently employed during the data pre-processing phase, such as when auto – encoder purge visual data to create better-looking pictures.
Some key distinctions between supervised and unsupervised learning

Distinctions in their different approaches
The two methods differ most noticeably when labelled datasets are used. Unsupervised learning algorithms, to make it short, do not use labelled input and output data (Ashrafuzzaman et al., 2020). In supervised learning, the algorithm “learns” from the training data by recurrently forecasting the data and adjusting for the correct solution. Although supervised learning models necessitate human involvement up front to classify the data properly, they are much more precise than unmonitored learning methods.
The underlying structure of unlabeled data is determined by unsupervised learning models, which remain independent. Be aware that they still necessitate some human involvement in the output variable validation process. For instance, an unsupervised learning model can identify that online shoppers frequently purchase bundles of related goods.
The primary objective of supervised learning is to forecast results for updated information. The kinds of outcomes that one can foresee are already recognised to him. The target of an unsupervised learning algorithm is to retrieve a degree of cognitive from massive amounts of new data. The machine learning algorithm determines what is unique or fascinating about the dataset.
Complexity: Supervised learning is a straightforward machine-learning method that is recurrently calculated using Python(/R) (LeDell, and Poirier, 2020). In unsupervised learning, substantial quantities of unredacted data must be analysed using strong tools. Unsupervised learning models are significantly more challenging because they require a large instructional set to produce the desired results.
Applications encompass detection techniques, computational language teaching, weather prediction, and project planning. Supervised learning methods are well adapted for these fields. Unsupervised learning, on the other hand, is ideal for imaging techniques, actionable insights, and intrusion detection systems.
Results versus Insights
Unsupervised learning has different objectives than supervised learning. In contrast to the latter, which focuses on drawing novel conclusions from vast amounts of novel data, the former is concerned with forecasting outcomes for newly introduced data. In contrast to unsupervised learning, where users are hoping to uncover something novel and unexplored, supervised learning gives users an idea of the results they can anticipate.
Cons: Supervised training models can be time-consuming and requires accurate labelling of the input and output variables. On the contrary when one is having an individual intervention for the purpose to validities the output variables along with unsupervised learning methods can be considered to prepare the widely inaccurate and faulty outcomes.
What learning process would be better to choose
Choosing the best strategy for a given situation depends on how the data scientists evaluate the use case, the volume and structure of the data, and both. The following steps should be taken when making decisions.
Analyzing the input data: It’s critical to assess whether the data are labelled or unlabeled and to determine whether one has access to experts who can support additional labelling.
Setting objectives the task at hand is to determine whether there is a consistent, well-defined problem to solve or if the algorithm needs to foresee new problems.
Examining the available algorithms: Here, the task is to determine whether any algorithms have the same dimensionality as what is required and whether they can support the data volume and structure or not.
Summary
Big data classification can be very difficult with supervised learning, but the outcomes are very reliable and accurate. However, unsupervised learning can easily implement huge amounts of data. However, the data grouping lacks transparency, and the probability of obtaining false results is higher. Because supervised machine learning requires more manual data preparation than unsupervised learning does it is a better and simpler learning strategy to use. With supervised machine learning models, it is impossible to uncover previously unidentified patterns in data. Unsupervised learning ensures this capability. Unsupervised learning is still thought to be less accurate than supervised learning. This is so that supervised learning algorithms, as opposed to unsupervised learning algorithms, can learn from a training dataset.
References
- An introduction to machine learning (2023) GeeksforGeeks. GeeksforGeeks. Available at: https://www.geeksforgeeks.org/introduction-machine-learning/ (Accessed: February 13, 2023).
- Ashrafuzzaman, M., Das, S., Chakhchoukh, Y., Shiva, S. and Sheldon, F.T., 2020. Detecting stealthy false data injection attacks in the smart grid using ensemble-based machine learning. Computers & Security, 97, p.101994.
- Bell, J., 2022. What is machine learning?. Machine Learning and the City: Applications in Architecture and Urban Design, pp.207-216.
- LeDell, E. and Poirier, S., 2020, July. H2o automl: Scalable automatic machine learning. In Proceedings of the AutoML Workshop at ICML (Vol. 2020).
- Osisanwo, F.Y., Akinsola, J.E.T., Awodele, O., Hinmikaiye, J.O., Olakanmi, O. and Akinjobi, J., 2017. Supervised machine learning algorithms: classification and comparison. International Journal of Computer Trends and Technology (IJCTT), 48(3), pp.128-138.
- Salo, F., Nassif, A.B. and Essex, A., 2019. Dimensionality reduction with IG-PCA and ensemble classifier for network intrusion detection. Computer Networks, 148, pp.164-175.
- Soni, D. (2020) Supervised vs. unsupervised learning, Medium. Towards Data Science. Available at: https://towardsdatascience.com/supervised-vs-unsupervised-learning-14f68e32ea8d (Accessed: February 13, 2023).
- Sreedhar, C., Kasiviswanath, N. and Chenna Reddy, P., 2017. Clustering large datasets using K-means modified inter and intra clustering (KM-I2C) in Hadoop. Journal of Big Data, 4(1), p.27.
- Supervised vs. unsupervised learning: What’s the difference? (2023) IBM. Available at: https://www.ibm.com/cloud/blog/supervised-vs-unsupervised-learning#:~:text=To%20put%20it%20simply%2C%20supervised,adjusting%20for%20the%20correct%20answer. (Accessed: February 13, 2023).
- Supervised vs. unsupervised learning; which is best? | Alteryx (2023) supervised vs unsupervised-learning. Available at: https://www.alteryx.com/glossary/supervised-vs-unsupervised-learning (Accessed: February 13, 2023).